

This blog post highlights the importance of retrieval for building AI products that feel like AGI, and goes over some of the most common pitfalls of current search techniques. It presents new retrieval benchmarks to help developers pinpoint the most common failure modes for their use cases.
Introduction
Artificial General Intelligence is about developing AI that can learn new information on the fly, just like a human being you might hire and train. Despite Large Language Models scoring in the top 10% across nearly every STEM subject, we still haven’t reached AGI. Why? Because we need better contextualized models that can connect to knowledge bases and seamlessly retrieve information as effortlessly as human memory. Yet, despite this critical bottleneck in retrieval, the vast majority of AI systems in production rely on basic semantic search to provide context. A single retrieval call into a vector database powers most Retrieval-Augmented Generation systems today. If you’ve tried using models like these, you know exactly how limited they are in truly understanding your data.
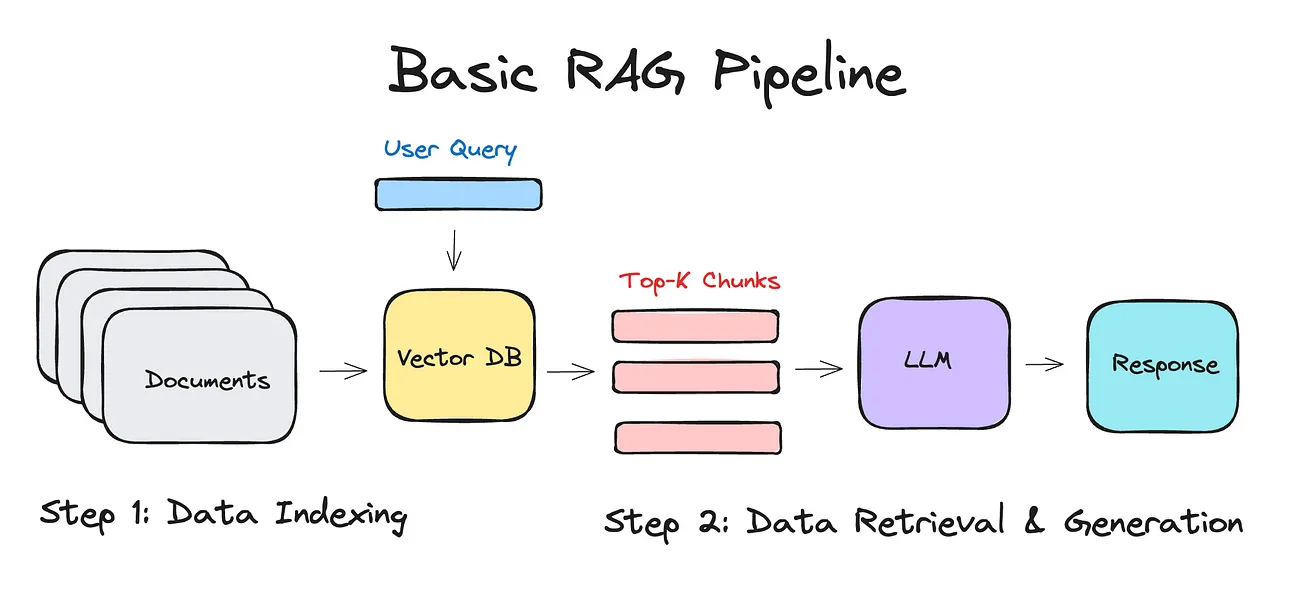
Not only is this pipeline unable to do anything other than a simple needle in haystack, but the worst part is that very few developers have evaluations to formally verify where and when this pipeline just does not work.
At ZeroEntropy, we have done this work of creating robust evaluation pipelines for retrieval, and looking into thousands of datapoints of actual user queries to clearly classify and determine exactly where and when semantic search starts to break down and provide missing or hallucinated results.
In this blog post, we will go over some of the most common pitfalls we have found, and we will discuss retrieval benchmarks to help developers pinpoint the most common failure modes for their use cases.
A few examples of why the current form of semantic search won’t solve the retrieval problem
We spent weeks debugging retrieval pipelines and solving the most common failure modes of simple semantic search systems. We identified dozens of examples where neither semantic nor keyword based approaches are capable of finding the needle in the haystack.
Here we will share three of the most common and basic failure modes that you probably currently have in your stack.
Here we will share three of the most common and basic failure modes that you probably currently have in your stack.
Negated Semantic Queries
“Which electric vehicle articles do not include any reference to Elon Musk?”
- Both keyword and semantic searches will immediately retrieve specifically the electric vehicle articles that include a reference to Elon Musk.
Multi-Hop Queries
“If the acquiring company fails to hold a shareholder’s meeting, what is the penalty?”
- To answer this query, you need to work step-by-step. You would need to find the paragraph that says what happens when you fail to hold a shareholder meeting. Let’s say that such a search reveals that the agreement will be terminated in that circumstance. Then, you must search for what penalties are incurred by terminating the agreement. A simple semantic search will return paragraphs about shareholder’s meetings, and it will also return paragraphs about any kind of penalty — but, it will fail to link the two and realize that specifically a “termination penalty” must be boosted to the first place result.
Fuzzy Filtering Queries
“What diagnostic methods are suggested for early-stage cancer, in papers with a sample size of over 2000”
- Sample sizes often occur in the introductory paragraph of a medical research article. Meanwhile, the specific diagnostic method is likely mentioned deep the article. So, these two pieces of information often do not occur in the same chunk. Your RAG pipeline will be happy to show diagnostic methods for early-stage cancer in articles that do not match the requested sample size — Not only that, but the correct answer will be almost impossible to find if “over 2000” is a rare filter.
How are you evaluating your retrieval pipeline?
Through conversations with hundreds of developers, we’ve discovered that retrieval evaluation is often overlooked, despite the impact on an AI’s intelligence and hallucination rate. In most cases, evaluations occur at the end-user stage, either through direct feedback mechanisms like thumbs up/down ratings. However, few have a method of associating “thumbs down” ratings with exactly what went wrong and where. Was it a UX problem? Or an LLM hallucination? Did the retrieval pipeline fail, or did the corpus simply lack the correct information. Currently, these questions are typically addressed by manually reviewing queries — a process that is labor-intensive, inconsistent, and impractical at scale.
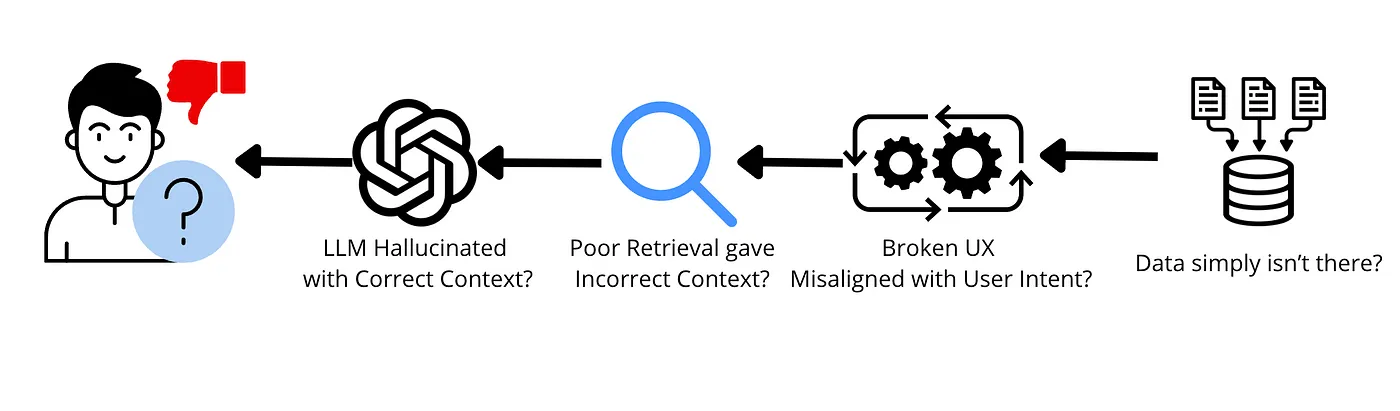
Evaluating retrieval is a key step to building a useful and reliable AI product. But doing so is hard. LLM evaluations only require an (Input, Output) pair. Meanwhile, retrieval benchmarks require the query, a snapshot of the entire corpus at that exact point in time, along with ground truth citations into exactly what the correct retrieval results should have been, which often span across multiple documents.
Building such a benchmark is extremely hard. We know first-hand what it’s like, when we built the first comprehensive retrieval benchmark over complex legal contracts.

But, luckily, there is hope. We strongly believe LLMs can and should be used to autonomously define and build benchmarks to compute deterministic metrics like recall, precision, mean reciprocal rank, etc.
That’s why we are currently building an open-source benchmark creation framework that we will release soon. If you’d like to contribute, or if evaluation is something you’re curious about, feel free to reach out to us.



