
SHARE
TLDR —
Today, we are releasing ze-rank-1, our new cross-encoder reranker that boosts top-k precision over any first-stage search.
zerank-1 increases the accuracy of any initial search system, from BM25 to OpenAI embeddings, showing up to +28% in NDCG@10 across domains
zerank-1 also outperforms Cohere's latest rerank-3.5 and Salesforce's recent LlamaRank, with up to 18% increase in NDCG@10 in areas like Finance or STEM
We tested zerank-1 using our custom zbench evaluation framework and achieved 12% better accuracy compared to Gemini 2.5 Flash used as a reranker
Available now via API, Hugging Face at $0.025 per million tokens: half the cost of Cohere's rerank-3.5. zerank-1-small is also available through our partner Baseten.
Trained on synthetic SFT pairwise data with ELO-based ranking for calibrated scores,
a novel approach never attempted before (read more here).The weights are released under non commercial license, with a fully open-source 1.7B parameter counterpart.—
What Is a Reranker and Why You Might Need One
A reranker is a cross-encoder neural network that rescores and reorders an initial set of candidate documents based on query–document relevance. By processing each query–document pair together, it picks up subtle semantic signals that keyword or bi-encoder methods miss. Rerankers slot in after your first-stage search, whether BM25, vector search, or hybrid, to maximize precision in your top k results.Learn more in our guide to rerankers and why they matter: What Is a Reranker and Do I Need One?
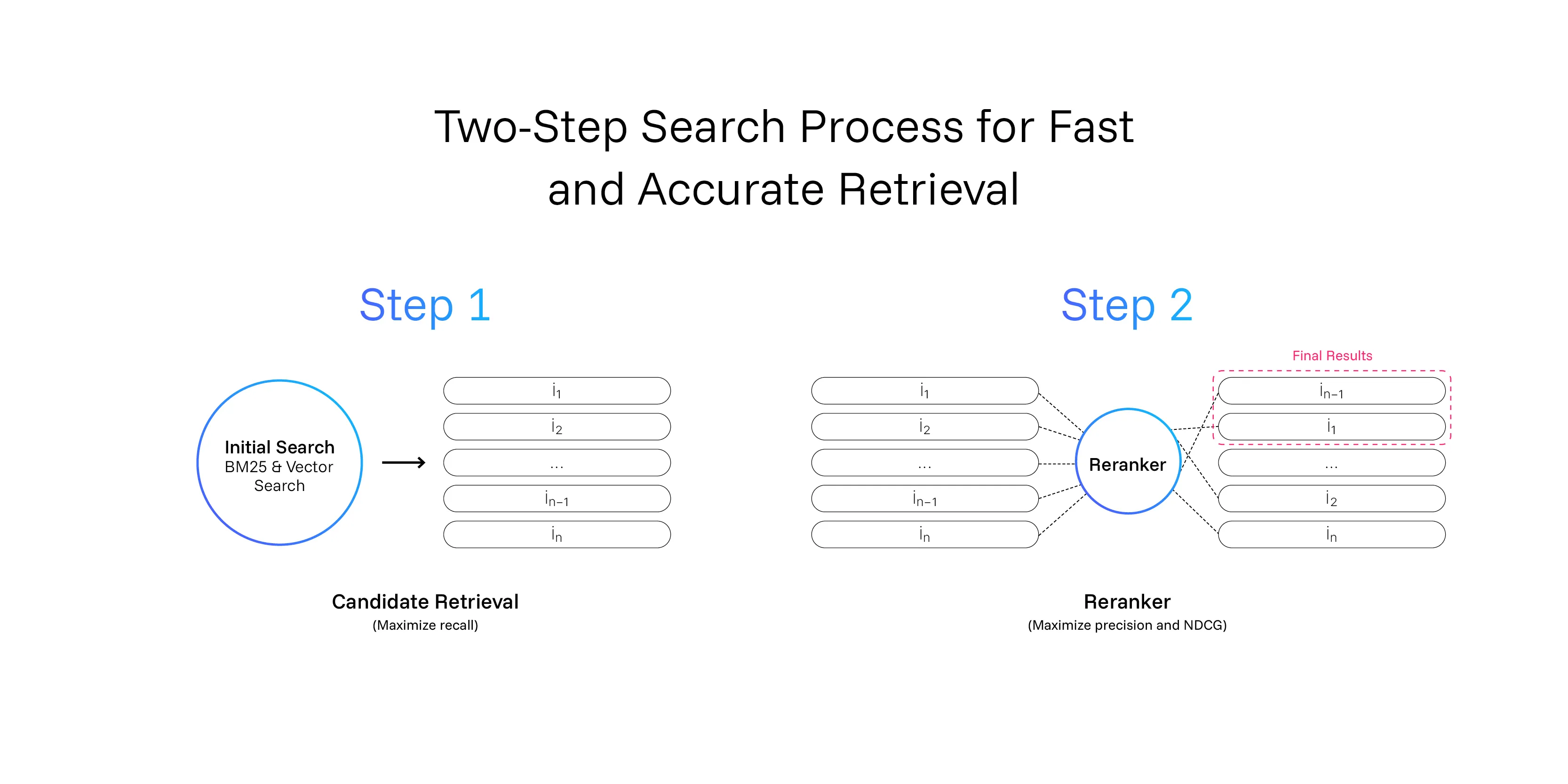
The model takes a query-document pair as input, and returns a calibrated score you can use to rerank your initial results. It’s simple, fast, and makes your search feel like magic.
Performance
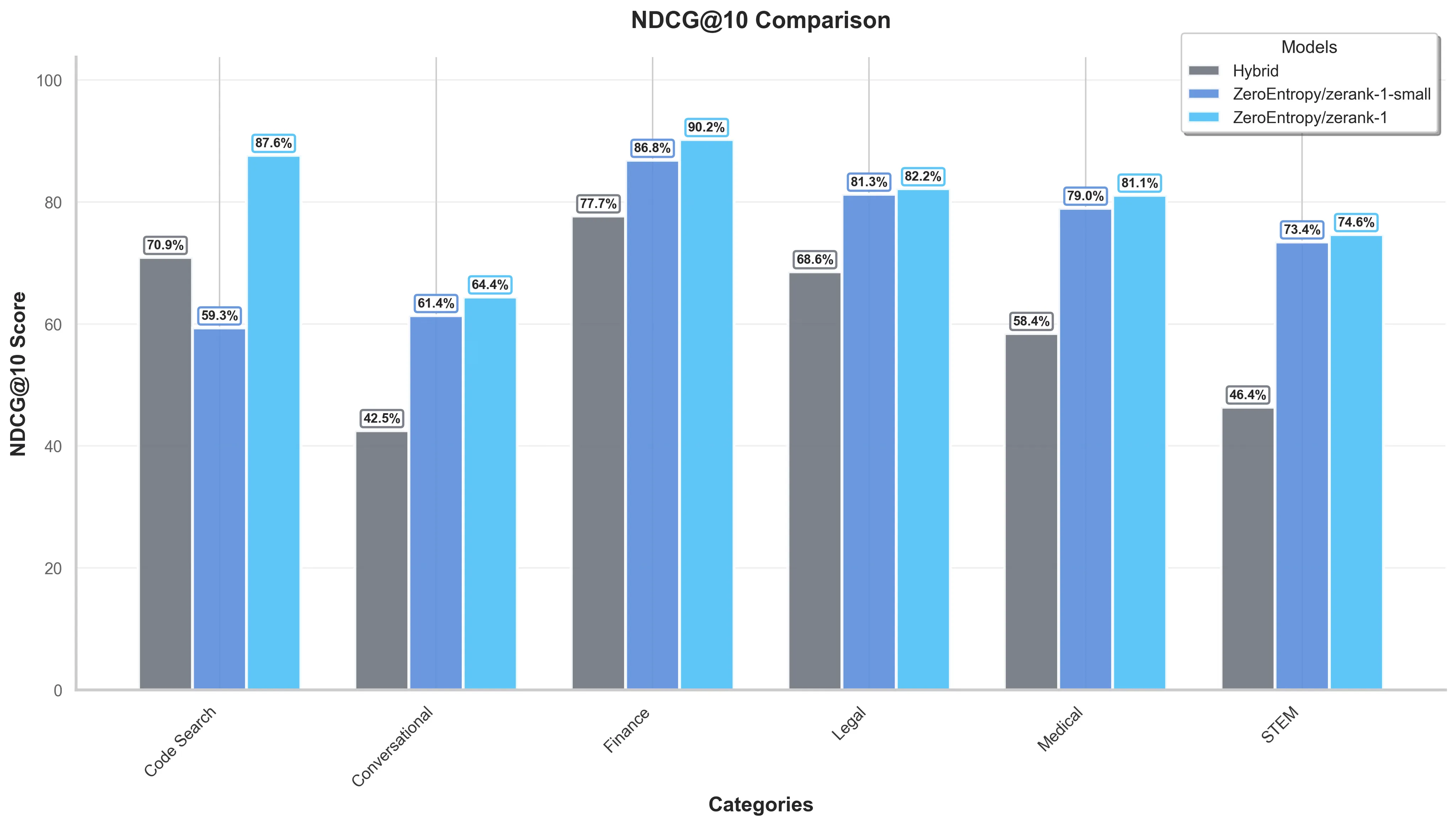
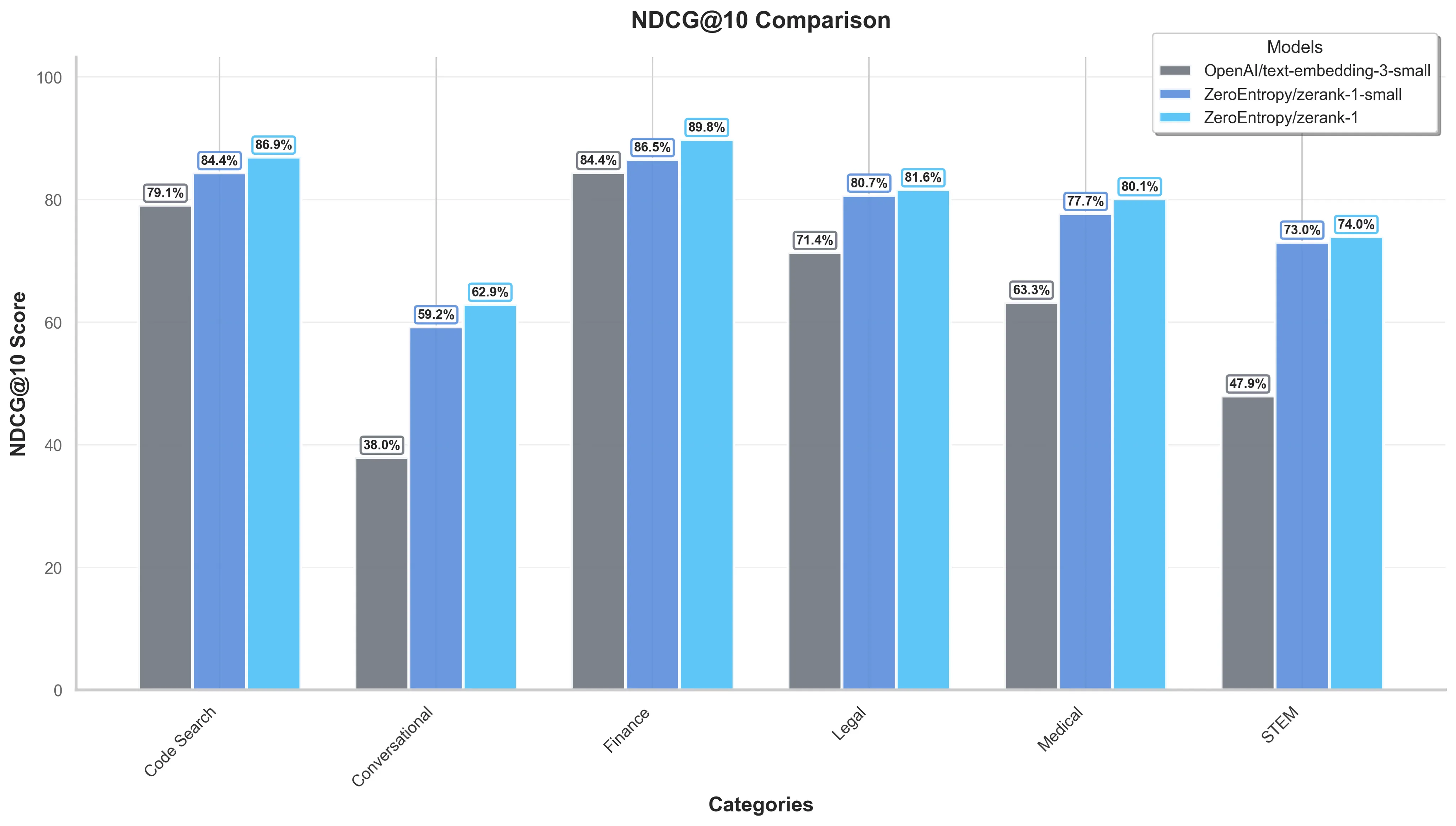
Using ZeroEntropy's reranker can boost the accuracy of any first-stage retrieval pipeline. We compared the NDCG@10 of BM25, OpenAI's text-embedding-small, and a Hybrid combination of both using Reciprocal Rank Fusion. We observe that our zerank-1 boosts NDCG@10 for all initial search methods, and across domains.
Below are benchmark results of both zerank-1 and zerank-1-small when applied on top of OpenAI's text-embedding-small as a first-stage retrieval.
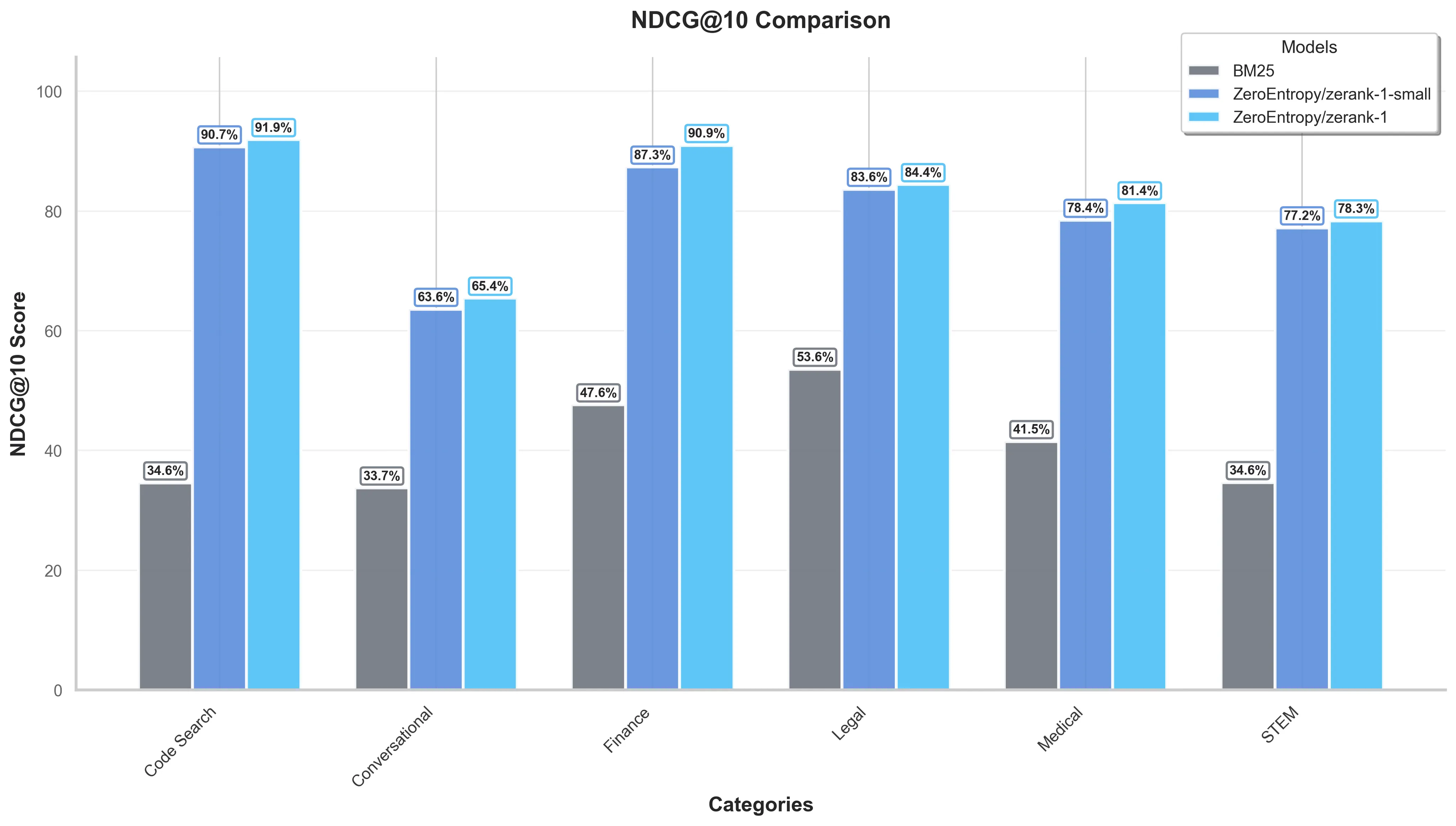
Using BM25 as a first stage retrieval, zerank-1 improves NDCG@10 even further:
Below is a snapshot of how zerank-1 improves NDCG@10 across our public benchmarks when applied on top of OpenAI's text-embedding-small as a first-stage retrieval, compared to other popular retrieval providers:
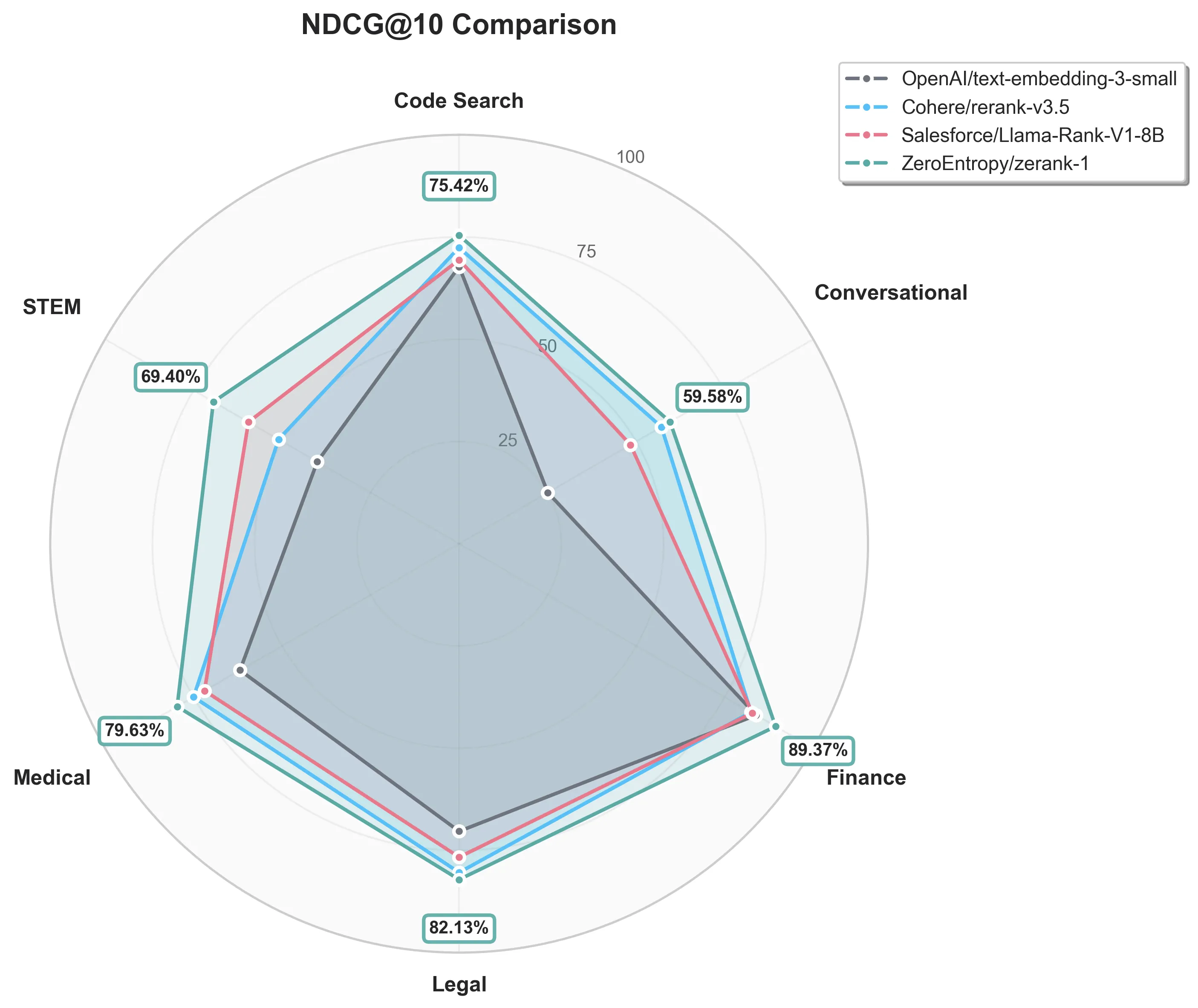
Although some NDCG@10 values in the chart may seem low at first glance, scores in the 50-85 range are actually very strong in practice. NDCG (Normalized Discounted Cumulative Gain) is a strict metric that heavily penalizes misranking of relevant documents, especially near the top positions — so even a score of 50 often means that the most relevant item is ranked at least second.Additionally, we tested the capabilities of a large LLM using our zbench framework which allowed us to benchmark Gemini 2.5 Flash as a reranker. The results below show that both our models considerably outperform Gemini:
Real-World Customer Gains
We’ve already deployed zerank-1 in beta with select customers. Here are four illustrative cases on private data:
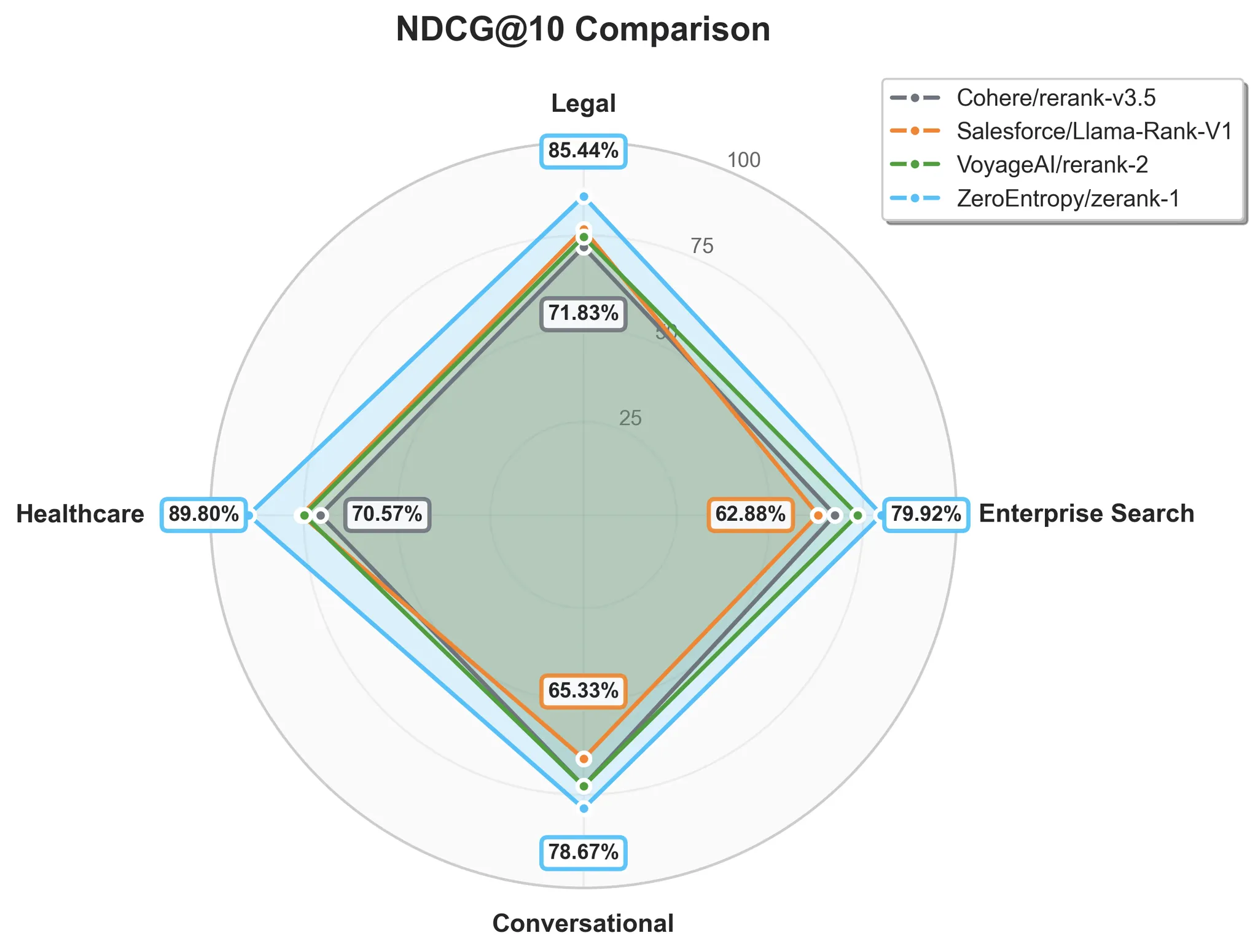
Benchmark results
Model | NDCG@10 | Latency (12 KB) | Latency (150 KB) |
|---|---|---|---|
Jina rerank m0 | 0.7279 | 547.14 ± 66.84 ms | 2 543.8 ms ± 2 984.9 |
Cohere rerank 3.5 | 0.7091 | 171.5 ms ± 106.8 | 459.2 ms ± 87.9 |
ZeroEntropy zerank-1 | 0.7683 | 149.7 ms ± 53.1 | 314.4 ms ± 94.6 |
zerank-1 is:
~12 % faster than Cohere 3.5 on small payloads (149.7 ms vs 171.5 ms)
~31 % faster on large payloads (314.4 ms vs 459.2 ms)
4× faster than Jina on 12 KB queries
All while delivering the highest NDCG@10 of the group.
Price and Availability
Both zerank–1 and zerank-1-small are available:
today via our API, and on the Hugging Face Model Hub.
zerank-1-small is completely open-source under an Apache 2.0 license, and available through our partner Baseten.
Pricing is simple and transparent:$0.025 per million tokens - Half the cost of Cohere and Voyage latest rerankers.
Integrate the reranker in minutes! See our docs at:https://docs.zeroentropy.dev/reranker or at contact@zeroentropy.dev for enterprise terms.
How We Trained it
We built two LoRA-fine-tuned cross-encoder variants, a 4B parameter base model and a 1.7B one. Our pipeline consists of training an intermediate pairwise model as well as leveraging the power of ELO rankings.
To our knowledge this is the first scalable pipeline that turns synthetic pairwise judgments into an ELO-based ranking model. You can read more here.
Learn more at docs.zeroentropy.dev
Reach out to chat with our founding team at founders@zeroentropy.dev or join our Slack community.

RELATED ARTICLES



