LegalBench-RAG, the First Open-Source Retrieval Benchmark for the Legal Domain

Evaluating Legal RAG systems. Source: https://arxiv.org/abs/2408.10343
As the legal industry rapidly embraces artificial intelligence (AI) technologies, a critical gap has emerged in the ecosystem — the lack of a challenging, open-source, dedicated benchmark for evaluating the retrieval component of Retrieval-Augmented Generation (RAG) systems in the legal domain.
Why do we need LegalBench-RAG?
LegalBench is the current benchmark that’s primarily used by Legal AI companies to assess their systems, but it does not test the most difficult part of any RAG pipeline — the retrieval step.
LegalBench tasks have two inputs (Context, Query), and one output (Answer). This is great at benchmarking an LLM’s ability to reason. But it does not benchmark the ability of a retrieval system to extract that Context from a large corpus of millions of characters. If your RAG pipeline is performing poorly, you need to ensure that both your retrieval and generation steps are individually scoring well on benchmarks.
This is why we need an open-source retrieval focused benchmark.
The benchmark needs to be legal-focused because the jargon used in the complex legal documents can greatly alter the performance of certain retrievers. For example, our paper shows that a general-purpose model such as the Cohere reranker actually hinders the performance of the retrieval in a legal context.
This is why we need a legal-focused benchmark.
LegalBench-RAG aims to fill this gap.
Introducing LegalBench-RAG
Constructed by retracing the context used in the LegalBench dataset back to the original expert-annotated sources, this new benchmark consists of 6,858 query-answer pairs spanning a corpus of over 79 million characters. The dataset covers a diverse range of legal documents, including NDAs, M&A agreements, commercial contracts, and privacy policies. The paper introducing LegalBench-RAG can be found here: https://arxiv.org/abs/2408.10343

Composition of LegalBench-RAG
Key Features of LegalBench-RAG
Human-Annotated Accuracy
Precise Retrieval by providing the index spans of the answer in the ground truth
Diverse Legal Corpus
LegalBench-RAG-mini, a curated subset of 776 query-answer pairs for rapid experimentation.
Significance of LegalBench-RAG
Creating high-quality datasets for legal AI is a very challenging and resource-intensive task.
For instance, the development of the CUAD dataset alone, which is used in LegalBench-RAG, required a year-long effort involving over 40 legal experts to generate 13,000 annotations. Considering the extensive manual review process, with each of the 9,283 pages reviewed at least 4 times and each page taking 5–10 minutes, the estimated cost to replicate the CUAD dataset is a staggering $2,000,000!
By providing a standardized evaluation framework, LegalBench-RAG empowers the industry to more easily compare and iterate upon the growing number of RAG techniques available today.
Comparing Dataset Difficulty
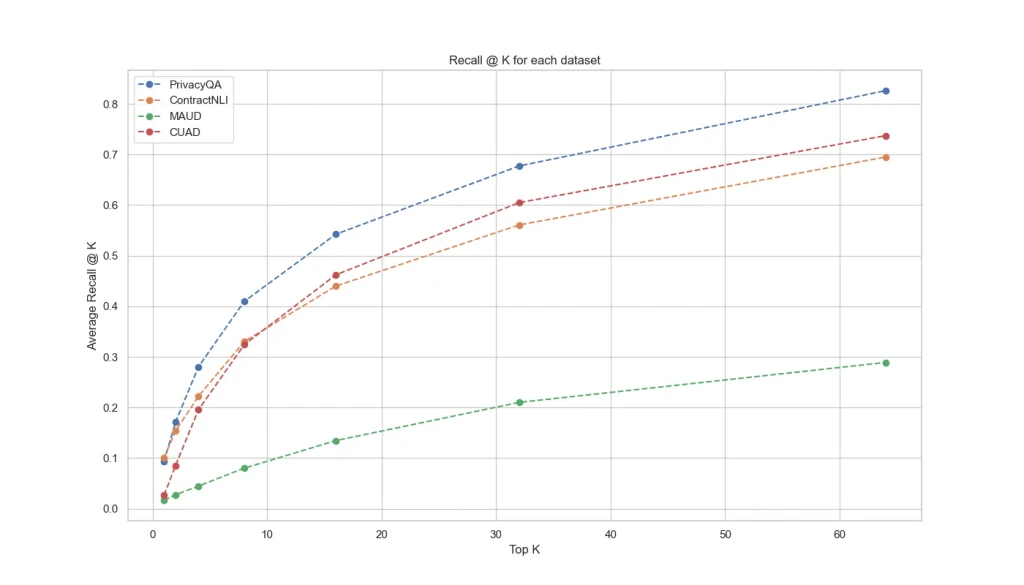
It is interesting to notice that the analysis of the different datasets in LegalBench-RAG revealed varying levels of difficulty.
Composition of LegalBench-RAG
Key Features of LegalBench-RAG
Human-Annotated Accuracy
Precise Retrieval by providing the index spans of the answer in the ground truth
Diverse Legal Corpus
LegalBench-RAG-mini, a curated subset of 776 query-answer pairs for rapid experimentation.
Significance of LegalBench-RAG
Creating high-quality datasets for legal AI is a very challenging and resource-intensive task.
For instance, the development of the CUAD dataset alone, which is used in LegalBench-RAG, required a year-long effort involving over 40 legal experts to generate 13,000 annotations. Considering the extensive manual review process, with each of the 9,283 pages reviewed at least 4 times and each page taking 5–10 minutes, the estimated cost to replicate the CUAD dataset is a staggering $2,000,000!
By providing a standardized evaluation framework, LegalBench-RAG empowers the industry to more easily compare and iterate upon the growing number of RAG techniques available today.
Comparing Dataset Difficulty
It is interesting to notice that the analysis of the different datasets in LegalBench-RAG revealed varying levels of difficulty.
The PrivacyQA dataset was the easiest, likely due to its more straightforward language around private company policies. In contrast, the MAUD dataset, covering highly technical mergers and acquisitions content, proved to be the most challenging, with models struggling to retrieve relevant information.
The poor performance of the general-purpose Cohere Reranker across the datasets highlights the need for specialized retrieval models tailored to the legal domain.
Conclusion
LegalBench-RAG introduces a new standard for comparing the quality of the retrieval component of RAG systems in the legal domain. The dataset and code are publicly available here: https://github.com/zeroentropy-cc/legalbenchrag
