

If you’re building AI systems like RAG or AI Agents, you’re probably familiar with semantic search and keyword search concepts.
Keyword Search (BM25)
Lightning-fast inverted-index lookups, perfect for exact matches when you know what you’re looking for (“try except syntax Python”), but recall drops when phrasing shifts (“how to catch errors in Python”).
Semantic Similarity
Nearest-neighbor vector search on precomputed vector embeddings. Much better at conceptual queries, as vectors are based on the semantic meaning of the content, rather than any particular keywords.
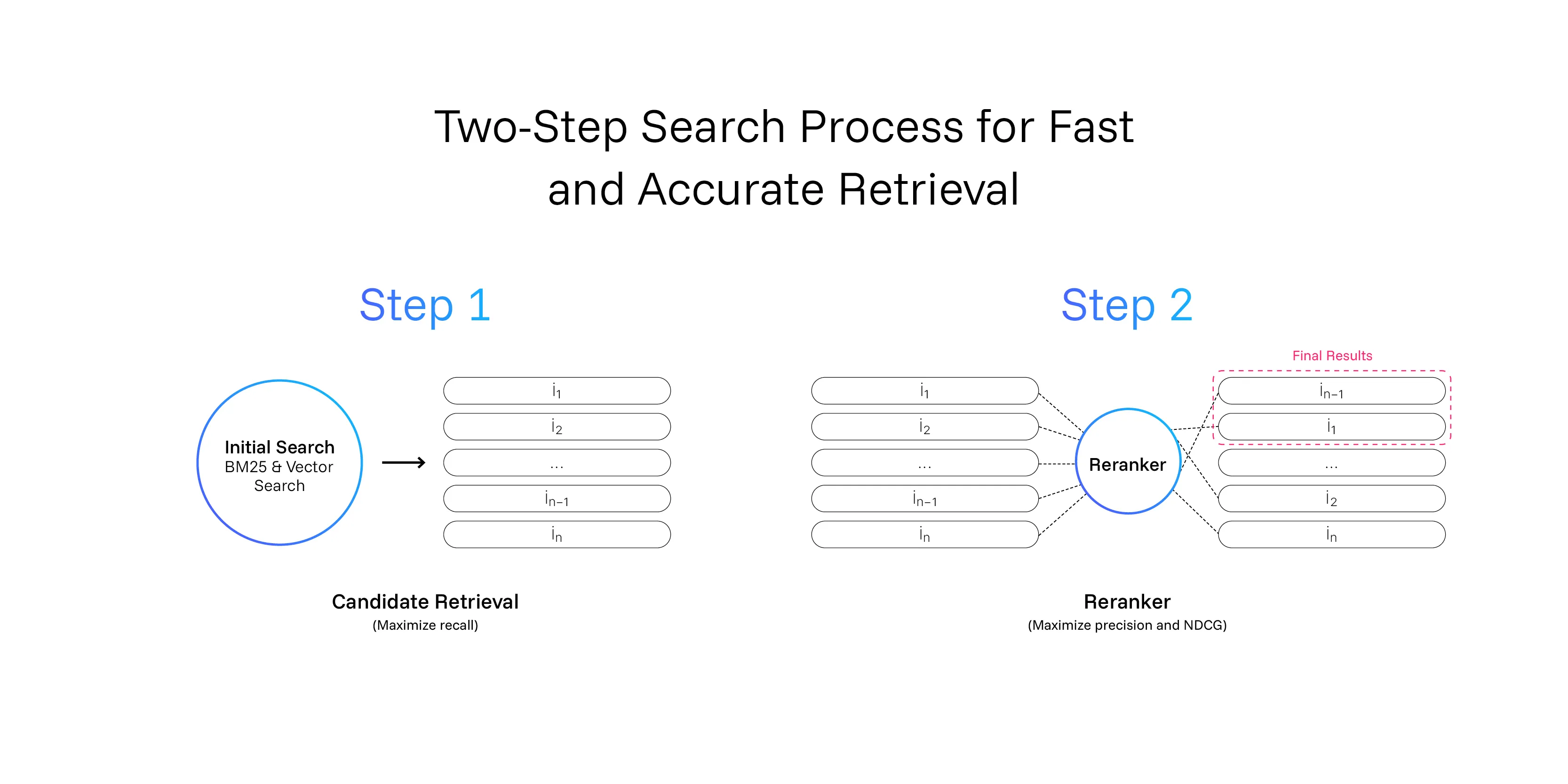
At ZeroEntropy, we combine those two methods in a hybrid setup to maximize recall. But recall alone isn’t enough. You might retrieve the correct answer out of millions of documents, but if it sits at position 67, your LLM, or your users, will never see it.
What is a reranker?
A reranker is a cross-encoder neural network that refines search results by re-scoring and reordering them based on query–document relevance.
Because the model sees the full text of both query and document at the same time, it is much more context-aware than first-stage methods where the document might have been encoded without knowledge of the specific query.
It can weigh the exact phrasing and context of query terms in the document and pick up subtle semantic relationships that the first stage search might miss.
Rerankers are modular in the sense that they can be used after any initial search pipeline, whether semantic, keyword-based, or hybrid.
Why add a reranker?
Fast keyword or vector retrieval can fetch many documents in milliseconds, boosting recall as you increase N. But flooding your downstream systems with too many hits lowers precision, wastes time, and makes LLMs more prone to hallucinations or losing the “needle in the haystack.”
For humans, only the first few results actually get manually inspected. Similarly, the “lost-in-the-middle” problem makes LLMs forget important pieces of information buried in a context that’s too large.
Performance & Scaling Trade-Offs
Vector Search (Logarithmic Scaling)
Embeddings precomputed offline. ANN algorithms (HNSW, IVF) search millions of vectors in ≈O(log N) time. Great for searching over an extremely large corpus, at very low latency.
Cross-Encoder Reranking (Linear in Candidates)
Each query–document pair is processed by a neural network, O(M) cost for M candidates. Impractical over the entire corpus, but efficient on a small set of candidates (e.g., M≤100). Balances quality vs. compute: fast first stage + targeted rerank.
When are rerankers most useful?
In most serious RAG or agent applications, especially those dealing with long, complex queries or high-stakes decisions, precision is paramount. A few hundred extra milliseconds to rerank can save you from LLM hallucinations and angry users.
There are situations where rerankers are even more useful:
-
Long, complex queries.
“Extract all clauses from vendor agreements signed in Q4 2024 that impose liquidated damages for late delivery and override any confidentiality provisions.”
A keyword pass will return every Q4 2024 agreement and any mention of “liquidated” or “confidentiality,” but it can’t prioritize the handful of clauses that satisfy both conditions. A reranker can learn to spot that rare intersection and boost those exact snippets to the top.
-
Adjacent-concept queries
“Show me support tickets about authentication failures”
If most tickets mention “denied access” or “invalid tokens” then a semantic search might not rank those very high. A reranker would be able to reason across all tickets retrieved and catch those adjacent terms and surface truly relevant cases.
-
Fuzzy-filtering queries
“Find all patient records where age > 65.”
Ages might be written as “born before 1959,” “sixty-eight,” or even stored under a “DOB” field. Also, embeddings and keyword matches might match any “65” number unrelated to an age. A reranker can reason and will be able to understand the specific way “65” is used in the sentence when determining whether or not it matches the condition.
If you’re building anything retrieval-heavy, rerankers will make your search results significantly more accurate.



