

Cherry-picked training examples can make embedding models look capable without genuine generalization. We tested 10,153 nouns and found that models like Qwen3 memorized the famous “let’s eat grandma” example rather than learning a general rule about commas—while ZeroEntropy’s zembed-1 shows consistent behavior as an emergent property of training.
”Let’s eat, grandma” vs “let’s eat grandma”: how embedding models encode the world
The sentences “let’s eat, grandma” and “let’s eat grandma” shouldn’t have identical embeddings—one is a dinner invitation, the other is a threat—but they should still be very close to each other due to their near-identical word usage. This linguistic example on the importance of a comma is well-documented, with the analogous phrasing using grandpa being less common. So what happens when we test embedding models on this distinction across thousands of nouns?
Using Qwen3 Embedding 4B and NLTK’s category person.n.01, we computed dot products between “let’s eat, noun” and “let’s eat noun” for 10,153 people-related nouns.
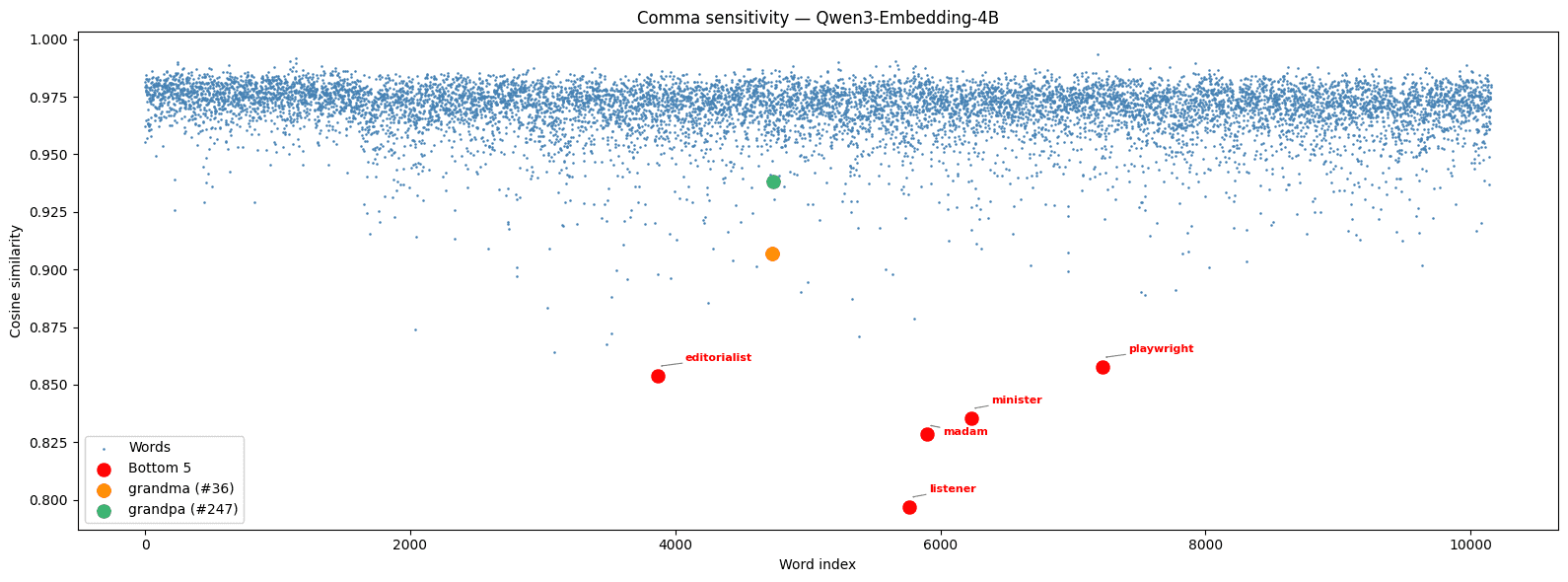
Most nouns cluster in a tight band around y = 0.975, meaning the model correctly treats the comma as a minor perturbation. But grandma and grandpa are dramatic outliers, pulled far below the band. And seemingly unrelated words like listener (y = 0.7969) give exceptionally low cosine similarity for no obvious reason.
Since grandpa and grandma differ by a single letter, we can run all 26 lower-case letter ablations of grandma (i.e. grandma, grandba, grandca, …) to check whether the effect is phonetic or semantic.
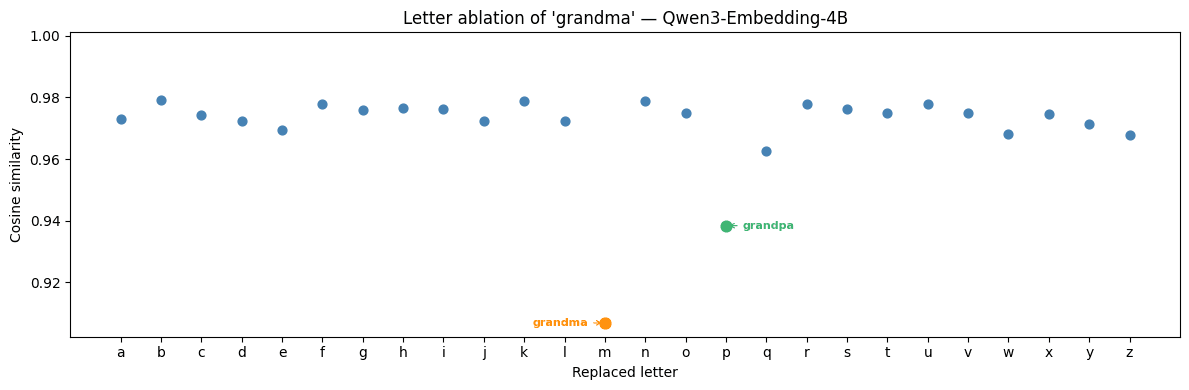
Everything except grandma and grandpa sits in the same y = 0.975 band, with the important caveat that none of these 24 other strings are genuine English words.
We hypothesize that the low placement of grandma and grandpa is a result of this specific linguistic example appearing with them in training data. The model didn’t learn a general rule about commas changing meaning; it memorized a famous example. Why other words like listener, madam, and minister also give anomalously low dot products remains a mystery.
What are embedding models?
In their broadest form, embedding models turn complex data from an abstract distribution into numerical vectors , also called embeddings, that live inside a well-defined vector space. Once objects are vectorized (embedded), similarity between them can be measured mathematically. Embedding models can be trained on a variety of datatypes: text, images, video, PDFs, audio, protein structures, and user histories/preferences.
The use cases range from finding ads that best fit your preferences to retrieving a song by your hum of it alone, or searching your Photos library for ginger cats (the last example involving a multi-modal model capable of embedding images and text to the same vector space).
From words to sentences: a brief history
Early systems such as Word2Vec converted individual words into vectors capable of capturing semantic meaning. Researchers found vectorially, by cosine similarity, that
meaning that of the three million words in the Word2Vec database, Queen was one of the nearest words to
| Word | Cosine similarity |
|---|---|
| king | 0.8449 |
| queen | 0.7301 |
| monarch | 0.6455 |
| princess | 0.6156 |
| crown_prince | 0.5819 |
If we loosely rephrase the similarity statement as
then both subtractions are similar by way of both being similar to an abstract gender vector: a vector which can be added or subtracted to move between the male and female version of a word. Similarly, “Paris” - “France” ≈ “Rome” - “Italy” implies there is a capital-ization vector which can move between a country and its capital. These examples illustrate how Word2Vec was trained to create semantic meaning along directions in space.
Modern embedding models such as ZeroEntropy’s zembed-1, a state-of-the-art open-weight model, go further: they perform search and retrieval on sentences and paragraphs by outputting normalized vectors so that the similarity of two texts is determined by a dot product. The normalization is done so that we have the relation
A smaller angle corresponds to a larger cosine and dot product, hence a higher similarity. A retrieval task is framed as finding a vector from a database that is particularly close to an input vector. In the context of text embeddings, we say that we have a query for which we’re looking for relevant documents from a corpus.
Why embedding models work in practice
There are many reasons these models work, but three stand out.
Fast calculation
As a metric between two vectors, dot product is faster than Euclidean distance. Dot products are also a special case of matrix multiplications, operations which GPUs are designed to perform quickly in the range of billions or trillions of calculations per second. A related strength of GPUs is parallelization: for calculating all dot products between a set of queries and a set of documents, doubling the number of queries or documents requires less than double the time if the calculation is done as a single matrix multiplication which computes all dot products at once.
Offline storage
Collections of items which are static can be embedded once and saved for future use. Each retrieval task thus only needs one embedding to be calculated—the query—as long as the corpus embeddings were precomputed. Systems like Google couldn’t function if every search required a re-embedding of every webpage on the internet.
Approximate retrieval
Even with fast dot products and precomputed embeddings, searching billions of vectors exactly would be too slow. The solution is to use Approximate Nearest-Neighbor algorithms (ANN) which utilize geometric ideas to heuristically find the nearest document vector to a given query vector. One idea is to split our data into clusters and only search the most-relevant clusters for a given query. As an example, if we have items binned by the six colors of the rainbow, to search for an aquamarine bottle we can look in the blue and green bins and ignore the rest. In the context of a vector database, clusters are made by mathematical calculations on embeddings rather than human decision, but the underlying idea remains.
How are embedding models trained?
As with most machine-learning models, embedding models are trained on large-scale datasets. For text embeddings, this involves a massive text corpora from the internet for broad language understanding during pretraining and a smaller set of high-quality natural or LLM-generated and annotated tuples of text for finetuning .
First, an LLM is pretrained on the corpora using next-token prediction loss, a loss function based on the probabilities of the LLM to generate each token given all prior ones. For instance, given a training sample of the array of tokens [I, like, kittens, <EOS>] (<EOS> is an end-of-sentence token), the loss function would be
Although this objective is designed for LLMs rather than embedding models, it forces the model to learn representations that encode grammar, semantics, and world knowledge. By removing the final token-prediction layer and keeping the transformer layers which do the heavy-lifting, we can save the learned useful representations and augment the output to give embedding vectors.
During finetuning, the embedding model learns the proper geometry of the embedding space. This requires the use of contrastive loss techniques , the most common of which today is InfoNCE loss , albeit others such as pairwise and triplet loss can be additionally used. Given a batch of pairs (q₁,d₁),…,(qₙ,dₙ) where a query and a document are paired as relevant to each other, we compute the dot products of all queries over all documents as sᵢⱼ = qᵢ · dⱼ and use loss function
where τ is a hyper-parameter indicating temperature. Minimizing this loss function pushes each query qᵢ to have a large dot product with its matching dᵢ relative to all other dⱼ.
Where embedding models fail
Regardless of how an embedding model is trained, there are always two points of failure: data generation and data annotation. If you only train on legal documents, your embedding model will fail on medical records. If you only train on pairs which have the same number of characters, your embedding model will become a string-length classifier.
There’s also a more intrinsic challenge. Unlike a reranker which computes a relevancy score based on two texts simultaneously, embedding models have to output vectors for every text independently with the goal that every possible dot product makes sense. As a result, embedding models learn broad meaning but often fail on fine details where a small change in text greatly alters meaning: think of and’s, or’s, and not’s. This makes embedding models good at recall (the ability to pull up a collection of potentially relevant documents from a large corpus) rather than precision (the ability to assign the single most relevant document with the highest dot product). Applying a reranker to sift over the top documents pulled from an embedding model is a powerful technique to get precision without applying a reranker over every document for a given query.
In August 2025, Google DeepMind published On the Theoretical Limitations of Embedding-Based Retrieval, showcasing a reasonable dataset that embedding models struggle to retrieve from accurately. We recently made a summary video, but to give one example from the paper, the DeepMind team made the LIMIT dataset consisting of documents stating the likes of various people (“Olinda Posso likes Bagels, Hot Chocolate …”) and queries asking who likes certain objects (“Who likes Bagels?”) where each is answered by exactly two people. The difficulty stems from the fact that the embedding model needs to store a large number of independent objects—bagels can be generalized to any possible object—while the model only has a finite number of dimensions to save the fine details of every object a person likes.
The cherry-picking problem
When embedding models are improved to fix a specific failure mode, such as the LIMIT dataset, the fix often amounts to cherry-picking a narrow set of examples rather than solving the underlying limitation. For example, after the infamous “How many r’s are in strawberry” failure mode for GPT-4, newer models such as GPT 5.2 don’t struggle on this exact example but still fail on similar ones.

The training of embedding models runs into the same problem: models can be overfit on cherry-picked examples to give the appearance of genuine capability. In an ideal world, models should behave consistently—either reliably passing or failing a modality—rather than succeeding on isolated examples.
This brings us back to our opening experiment. The Qwen3 results suggest the model memorized the famous grandma/grandpa comma example from training data rather than learning a general rule. The question is: can an embedding model exhibit consistent behavior across this test without being explicitly trained on it?
zembed-1: consistency as an emergent behavior
We ran the same tests on ZeroEntropy’s zembed-1, which was never trained for the purpose of overcoming this example.
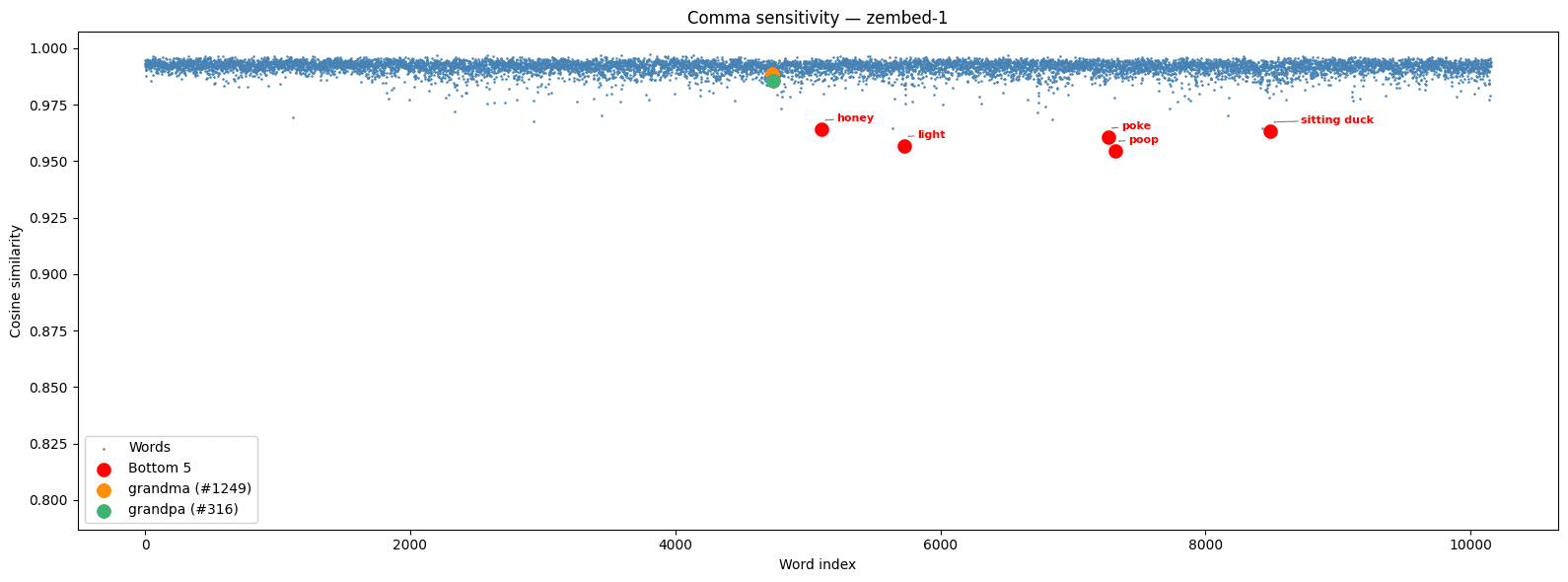
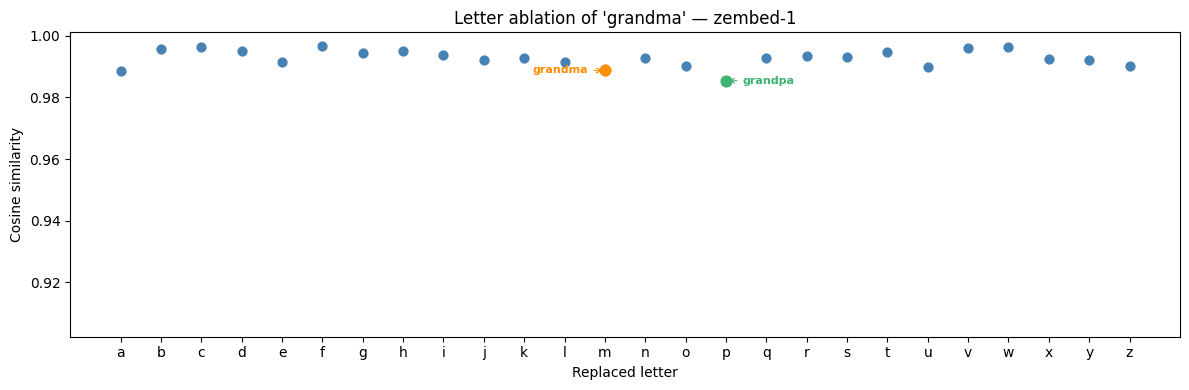
The improvement in consistent high cosine similarity appeared as an emergent behavior of our training of zembed-1. Mechanistic interpretability is notoriously difficult on large models, but these results give insight into how embedding models can be influenced by the data and annotations they are given. Whereas Qwen-3 shows scattered outliers driven by training data artifacts, zembed-1 maintains a tight, uniform band across the full noun space.
To learn more about how we approached training on our embedding model zembed-1, explore here.



